The Goal
I wanted to scrape target.com for receipts for my family budgeting program. But I’m sick of writing scrapers.
I tried a vision language model called Qwen3-VL. It can take a website screenshot and tell you what it sees. I vibe-coded a simple script to screenshot target.com, use playwright to identify and numerically label clickable elements and then have qwen identify the label of the clickable element that corresponds to an account login button. It worked! But not without memory issues.
This project created more questions than answers but I learned quite a lot about running local models for useful purposes.
What worked
The setup to get this to work
- Transformers
- Qwen3-VL-2B-Instruct
- Using transformers bits & bytes library to quantize to 4bits per weight
- Using playwright to annotate every clickable element on the page with a numbered red box
- Asking Qwen3-VL “What is the number of the box corresponding to the account login button”
Qwen correctly identified box 49 in the image as the account login button. I had playwright click it and it opened the login hamburger menu :)
Here’s the target homepage as the model saw it.
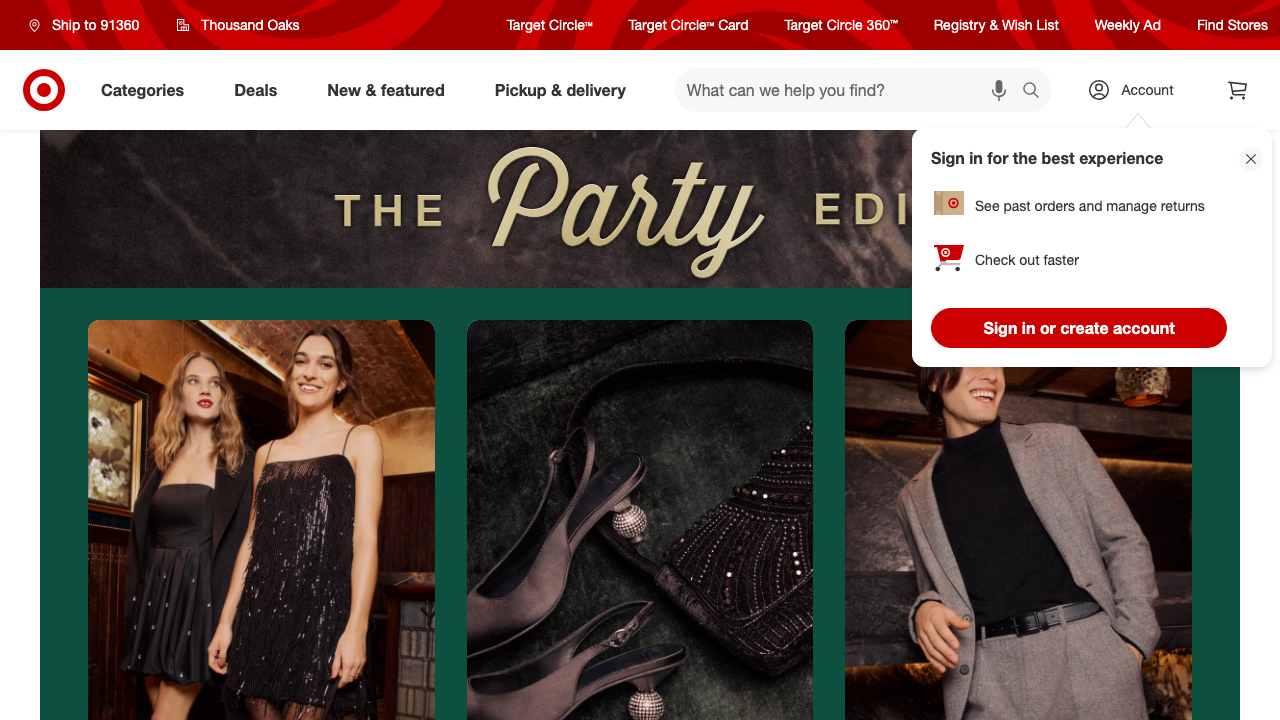
Here it is after annotating with Playwright.
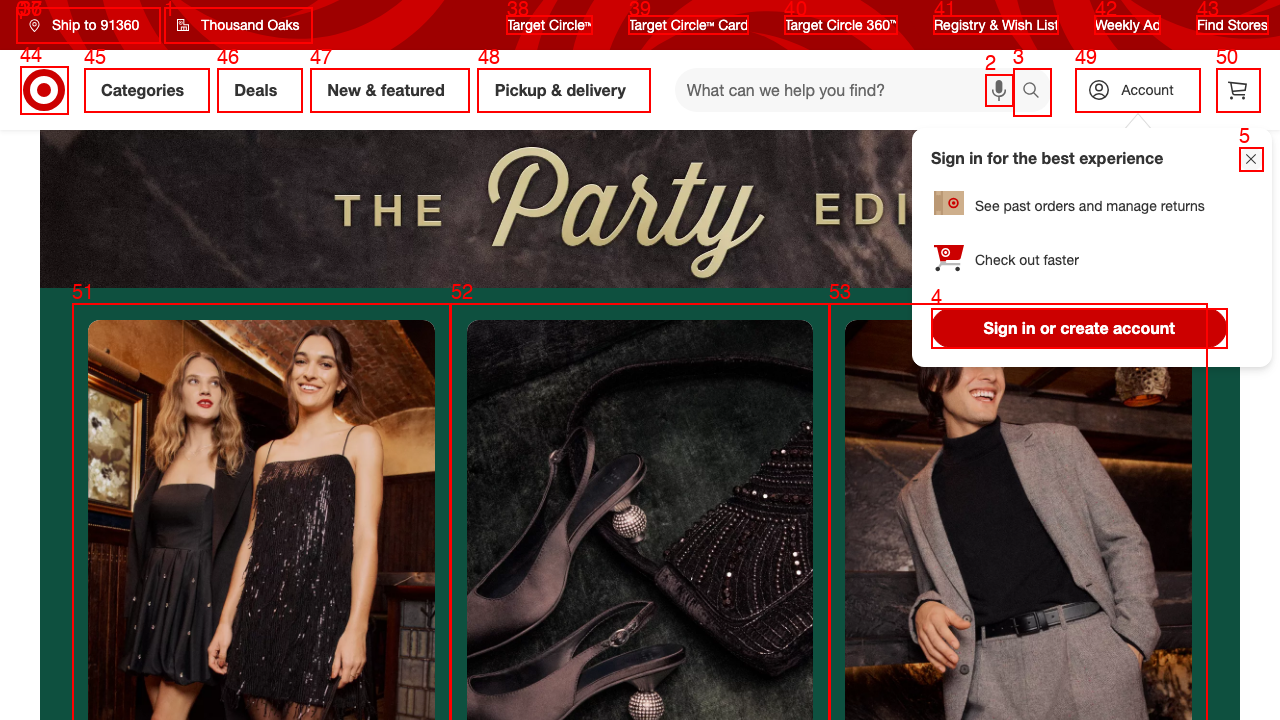
And here is the result after playright clicked on Account.
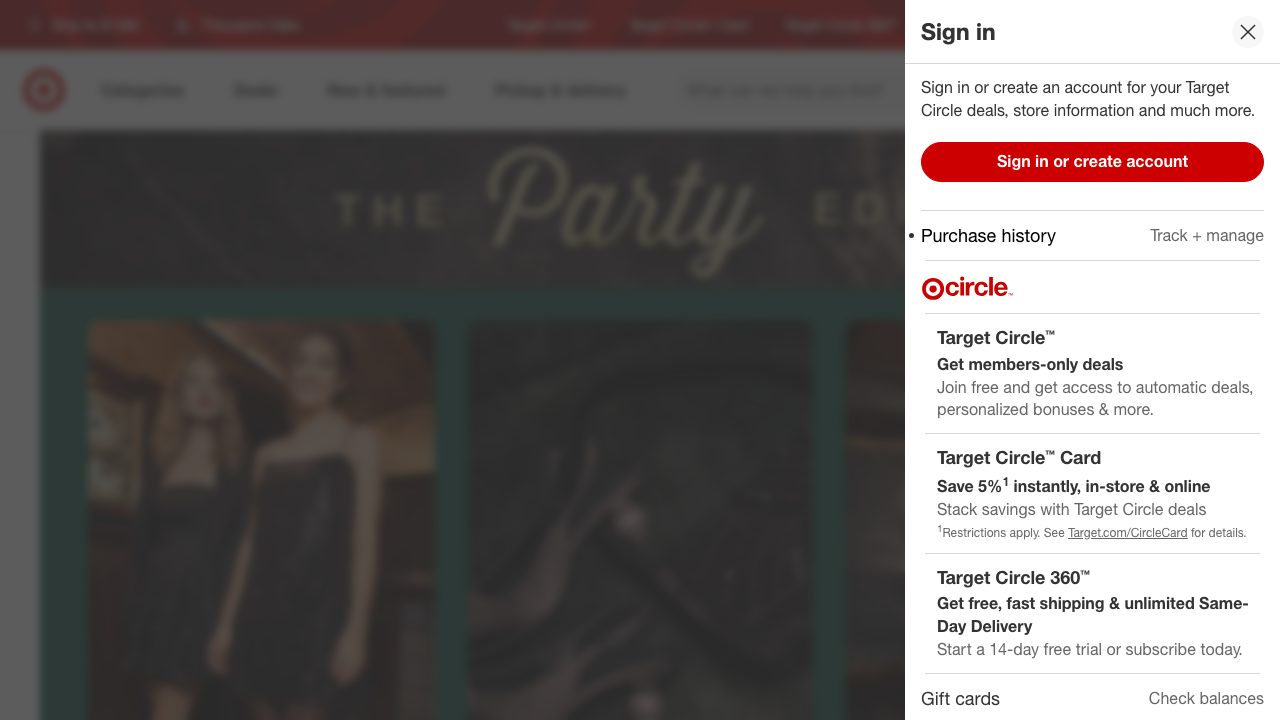
You can crank out anything I did above with Claude, transformers & some basic vibe coding skills. Where it got interesting is when 8B ran out of memory. I decided to dig much deeper.
Using llama.cpp however allowed me to run the 8b model directly. I wish I had done that from the start! :)
Here’s the source code.
What I learned
Transformers
- is a jack of all trades master of none library for AI. If you want serve models in lower memory environments, use llama.cpp.
- is a wrapper around pytorch. Any model you download from huggingface is deserialized into pytorch neural network matrices. For more training and control, you can use any pytorch training loop instead.
- Stores datasets as parquet files which useable with an OLAP database like duckdb.
Quantization
- Is a storage and compression optimization for speeding up how fast transformer layers are passed back and forth between gpu and memory only. If you quantize your model to 4 bit, the GPU has to uncompress the model in memory to 8 or even 16 bit because GPUs cannot do arithmetic on 4 bit numbers. It does not speed up how fast the layer is computed on the GPU in fact it slows it down due to the need to hydrate the quantized numbers.
- Quantization is fast and easy! At least for small models. It is simply reducing the space used by the weights in a simple truncation algorithm. It’s not retraining a model. It’s just compression.
Llama.cpp
- Is primarily for inference. You still need Transformers or Pytorch for training.
- Will quantize models too.
Vision Language Models
- Use a separate vision network to chop a picture into little squares each of which is assigned a token and sent to the language model, which it is trained on. They are not sending pictures directly to language models. I incorrectly assumed my memory errors were from the picture but pictures are not tokenized per pixel.
GPUs
- Primarily mostly spend their time loading and unloading layers of a transformer rather than doing computation.
Memory usage estimates
- Model footprint
Can be theoretically be calculated by multiplying the params by number of bytes per param. For the 4B model that would be 4 billion * 2 for 16 bits per param which gives 8 gigabytes. However, running get_memory_footprint() revealed something else.
model_name = "Qwen/Qwen3-VL-4B-Instruct"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype="float16",
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)
# Load the model with 4-bit quantization
model = Qwen3VLForConditionalGeneration.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto"
)
footprint = model.get_memory_footprint()
footprint_gb = footprint / (1024 ** 3)
print(footprint_gb)
>>> **2.62 gb**
For the 4b model with 4 bit quantization, this returned 2.62 gb! Since each parameter is 16 bits and they’re quantized to 4 bits, that’s roughly 1/4 of my 8gb estimate. But the extra .62 gigabytes multiplied by four would be an extra ~2.4gb inflated which i estimate would be a 10.4gb (8gb base + 2.62 observed offset) model.
Without the quantization, this code gave me an out of memory error saying RuntimeError: Invalid buffer size: 9.39 GiB.
model = Qwen3VLForConditionalGeneration.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto"
)
footprint = model.get_memory_footprint()
footprint_gb = footprint / (1024 ** 3)
print(footprint_gb)
>>> **9.39**
Nine and 4/10ths of a gigabyte is 1 gigabyte is much less than my estimate so I think that raises a question of what memory models are using beyond their parameters.
So I suppose there is more to a model’s footprint than just the parameters or my estimation number of parameters is wrong.
Just to confirm this idea there’s more to a model footprint than the weights, The 2B model had a footprint of 1.43gb with 4 bit quantization and 7.93gb without. 1.43 * 4 = 5.72 gb which is far less than 7.93 gb.
You need to use get_memory_footprint() to have the fastest understanding of how much memory a model needs.
- KV Cache (memory usage per token) Can be estimated with with the equation
Each transformer model has many layers and hidden dimensions but your context length is number of tokens and bytes per param is generally 2 bytes (even if you quantize to 4 bits because quantization is just a storage optimization technique).
Here’s an example of calculating how much the KV cache will use programmatically.
model = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-2B-Instruct",
quantization_config=quantization_config,
device_map="auto"
)
num_layers = model.config.text_config.num_hidden_layers
hidden_dim = model.config.text_config.hidden_size
processor = autoprocessor.from_pretrained("qwen/qwen3-vl-2b-instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "./path-to-target-screenshot.png",
},
{"type": "text", "text": "this image shows numbered markers overlaid on clickable elements. which number is the account button? reply with only the number."},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=true,
add_generation_prompt=true,
return_dict=true,
return_tensors="pt"
)
num_input_tokens = inputs['input_ids'].shape[1]
batch_size = inputs['input_ids'].shape[0] # will be 1 because we are only doing one prompt.
memory_usage_bytes = 2 * num_layers * hidden_dim * num_input_tokens * batch_size
memory_usage_gb = memory_usage_bytes / (1024 ** 3)
print(memory_usage_gb)
On my M1 with 16gb ram this runs out of memory with the 8b model but with the 4B model, returns 0.31 gb for the kv cache memory usage. The 2b model used 0.19gb for the kv cache memory usage. This is interesting because I thought the 4b model would use twice as much memory for the kv cache as the 2b model. I think this means a 4b model is not simply double the size as a 2b.
It’s important to calculate the memory usage per token programmatically rather than assuming you have enough memory.
Here’s a table to summarize the memory findings.
| model | quantized? | footprint | kv cache |
|---|---|---|---|
| 8b | no | n/a | n/a |
| 8b | yes | n/a | n/a |
| 4b | no | 9.39 gb | 0.31 gb |
| 4b | yes | 2.62 gb | 0.31 gb |
| 2b | no | 7.93 gb | 0.19 gb |
| 2b | yes | 1.43 gb | 0.19 gb |
Discovered Llama CPP > Transformers! :)
Using llama.cpp with the 8B model was as easy as.
llama-cli -hf Qwen/Qwen3-VL-8B-Instruct-GGUF
This loaded an 8b model on my apple m1 16 gb with NO PROBLEMS.
I wish I had tried this from the beginning but I had assumed going with transformers for everything would be fine.
Questions
This project created more questions than answers.
- What is Transformers doing under the hood that llama.cpp isn’t that causes it to run out of memory? It worked great with the 8B model! If I have 16 gb of unified memory, why would a 8b model quantized to 4 bit run out of memory? Perhaps quantization of the model causes memory spikes?
- Given a quantization factor and a model size per layer in parameters, is it possible to compute how fast a gpu will load and unload each layer?
- Could I have used flash attention on my m1 to speed up inference and lower memory usage with transformers?
Notes
ONNX is an open format for defining models, layers & operators so you can write a model in ONNX and use it across many devices and frameworks. However, ONNX seems to be a microsoft thing only and it doesn’t have the community that GGUF has. Plus google cloud does not support ONNX natively.